Give context, not bias
July 13, 2025
Related Projects

Context bias is all that matters
When creating AI systems or writing to an LLM, it is really important to realize that whatever is written inside the context window of the LLM, be it the system prompt, your own messages, or the LLM’s answer. Everything is considered to give a “bias” for the next generation of the next answer.
The reason why prompt engineering works is because you purposely write bias to steer the model into doing what you want it to do. This is what I consider “explicit bias”, things like:
Write in a very concise way, but still explaining things properly
But what’s more subtle is the concept of “implicit bias”, that is, all the other content that was generated by the LLM or written by the user, which is not part of explicit behavioral rules that you write for prompt engineering.
Local minima in machine learning
Let me try to give you an analogy with machine learning:
At a very high level, when trying to create a machine learning model, you have 3 main components:
- Your parameters: Those are the inputs of your model.
- An error evaluation function: It’s a function which, given a valid input, gives you how “bad” (or good) the model’s predicted answer is compared to the actual value.
- Your weights: Those make up the “brain” of your model, whose values you need to figure out so that the model does what you want it to do.
Overall, the purpose of training a model is “just” to find the correct weights, so that the error, calculated by using the error evaluation function, is minimal (we say, we want to minimize the error).
There are different kinds of model learning algorithms, but all of them can be seen as “walking” through the space of all possible weights, trying to find the one which minimizes the error function.
A pretty basic training function is one where you always head to the next set of weights that give you a lower error compared to the current weights. This is what is called a “greedy” approach. You stop when you reach a point where you cannot lower the error; at this point we say that we reached the “minima”.
The problem with this approach is that your search space might have more than one minima (called local minima), so how can you know that the local minima you reached is also the best minima? (called global minima)
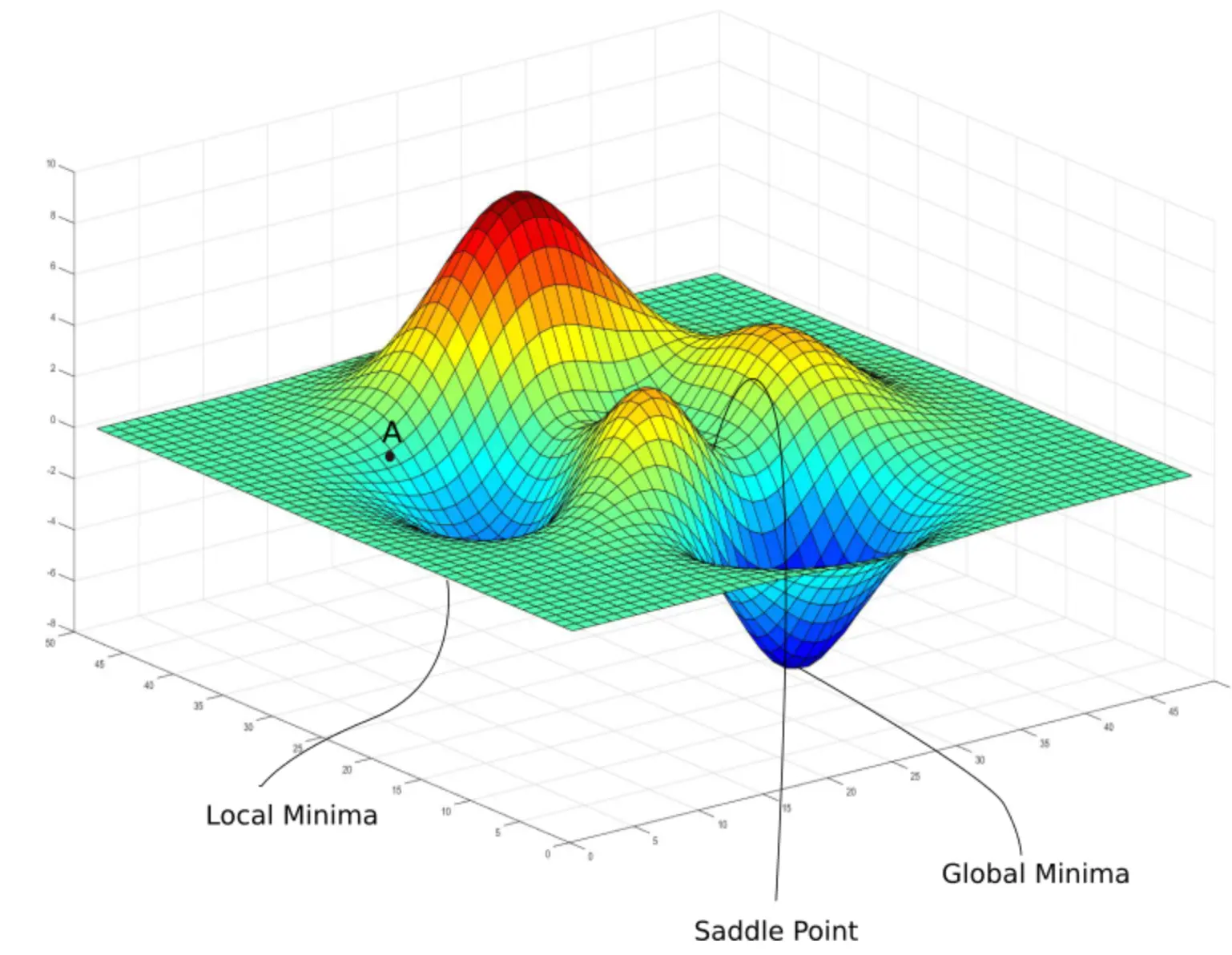
Look at this picture. This represents all possible error values for the evaluation function. We want to reach the lowest point, but say we reached the minima close to point A; how can we get out of it?
Other, not-so-simple algorithms decide to “go out” of the local minima, trying solutions that might be worse, but that lead to a solution that is better than the one that we currently found. Those algorithms tend to perform better than the simple greedy one that we discussed earlier, as they approximately try to visit the whole search space.
Implicit bias and local minima
Now that we explained local minima, let’s go back to LLMs.
Implicit bias is what I consider to be the “local minima” of a conversation with an LLM.
Have you ever experienced a situation where you ask the LLM for help in solving a task, and the LLM keeps cycling between solutions that always seem very similar?
This is implicit bias at play. The LLM is not able to escape the local minima that it reached and struggles to get out of it to explore other solutions. It seems to be behaving exactly like the simple greedy algorithm we saw previously, where we humans are the error function.
People at this point tend to either give up or create a new conversation with everything they learned in the prior conversation. This way they can remove bias, while still moving forward with the solution. This is the same as what we considered before. Trying to go out of our local minima by trying different, maybe worse solutions, to find the best one.
Avoid bias
When writing to an LLM, everything you tell it, as part of your question, can and absolutely will steer the answer towards what you wrote.
Imagine you are asking for advice. You may want to try to ask if a solution you thought is good (or alternatively, ask if the solution is bad). Depending on the level of confidence that you put in the prompt, the LLM might be biased towards giving you an answer that more closely aligns with what you wrote.
Say you are exploring solutions to a task you need to solve. Telling the LLM what you already tried will make the model answer you with solutions which are in some way related to what you already tried.
In both cases, your wording or prior solution is YOUR local minima. The LLM is not able to get out of it and perhaps suggest you a better answer, as it’s stuck from the bias you gave.
Another example is negative prompting. You are trying to ask an LLM to follow a set of instructions that it needs to follow when giving you an answer. You might notice that prior conversations with old prompts lead the LLM into doing something that you do not like.
You think “I don’t want it to do this, let me try to tell the LLM to avoid it”, which yes, might work sometimes, but this inevitably gives bias to the model, which at some point might hallucinate and do exactly the opposite of what you told it not to do.
Give context, not bias
Here are some general rules when trying to solve tasks with an LLM:
1. Be minimal but complete
When talking to an LLM, try to always give the least amount of information that you can, while still explaining all of the goals and requirements of what you are trying to solve.
2. Explore multiple conversations
Create a few chats asking the same question, see which of the chats gave you the most satisfactory answer, and continue from there.
3. Learn and iterate
If the LLM gets stuck, gather all the useful things you learned through the conversations you had, and add them as new requirements to the task you are trying to solve. This way you keep going forward, steering the model in the direction of the global minima, while still allowing the model to wander around and try different solutions which might be better than the one you currently found.
4. Examples vs. rules
Examples are better than rules: Examples give a way higher bias compared to rules, as the LLM has more powerful context that will lead the answer.
5. Think in bias
When prompting an LLM, imagine in the back of your mind how words, sentences, or examples that you wrote might involuntarily steer the thoughts of the model, and try to use more generic, less strict wording.
Further reading
I wrote another article about how bias behaves in thinking models, and how prompting the LLM to write its own bias can help it to solve tasks better.